
Building on Solana is a lesson in managing high-speed data under pressure. We sat down with a Senior DevOps Engineer to discuss why most teams struggle with transaction delivery and how they evaluate Solana RPC providers when moving from a prototype to a production-grade HFT or DeFi setup.
Q: What is the first thing developers get wrong about Solana RPC?
The biggest mistake is treating RPC like a simple API endpoint that just works. On other chains, you send a transaction and wait. On Solana, if your node isn’t properly peered or if the network is congested, your transaction might never even reach the leader.
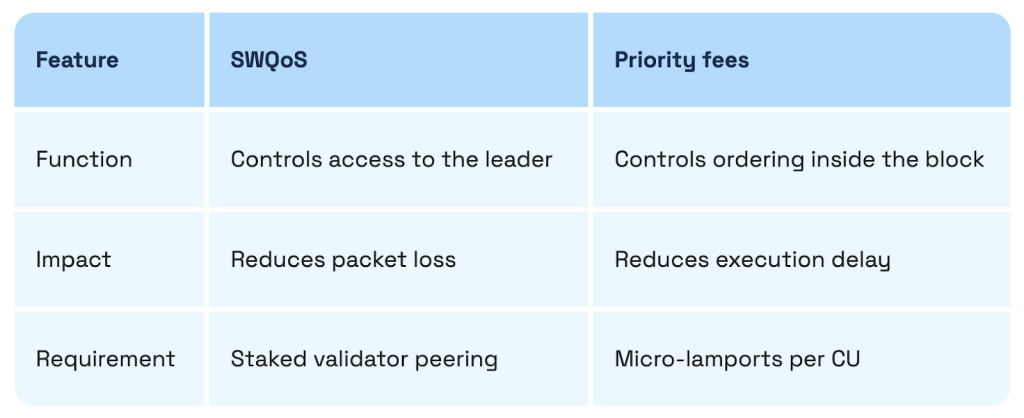
Developers often blame the network for “dropped” transactions when the issue is actually a bottleneck at the RPC layer. You need to know if your provider is actually staked or peered with a validator that has enough Stake-Weighted QoS (SWQoS) to get your packets through the door.
Q: Why is everyone moving toward gRPC instead of standard WebSockets?
WebSockets are fine for basic apps, but they’re heavy, and they break under load. If you’re running a trading bot or a real-time indexer, you can’t afford the overhead of JSON-RPC.
We’re witnessing a shift toward Yellowstone gRPC because it’s structured and much faster. It lets you stream account updates and transactions with almost zero lag. If your strategy depends on reacting to a price change in the same slot it happens, gRPC isn’t a luxury—it’s the baseline requirement.
Q: How do you handle the “noisy neighbor” problem on shared nodes?
On a generic shared RPC, you’re competing for resources with every other app on that server. During a hot mint or a market crash, everyone hits the node at once, and rate limits kick in. This is why we look for SaaS providers that offer tiered plans based on Compute Units (CU) rather than just raw request counts. It makes costs predictable.
For teams that have outgrown shared environments, moving to a dedicated node or a private cluster is the only way to guarantee that your indexing or execution won’t be throttled because someone else is spamming the network.
Q: What should a CTO look for when auditing an RPC provider?
Don’t just look at the monthly price. Look at the “heavy” methods. If you need to use getProgramAccounts to pull data, some providers will charge you a fortune or throttle you to a crawl. You also need to ask about bandwidth. Some services look cheap until you start streaming gRPC data and get hit with a massive bill for data egress.
Providers like RPC Fast have moved to a model with no bandwidth metering on paid plans, which is a huge relief for teams running heavy data-streaming workloads.
Q: Is “priority fee” enough to guarantee a transaction lands?
No. This is a common misconception. Priority fees only help you get ordered once you are inside the leader’s queue. But if the network is congested, your transaction might be dropped before it even gets to the leader. That’s where SWQoS comes in.
You need an RPC setup that is peered with a staked validator. If your provider doesn’t have a partnership with someone like bloXroute or a major validator, your high-priority fee is essentially useless because your transaction is stuck in the “unstaked” traffic jam.
Q: What’s the “sweet spot” for a scaling DeFi project?
Most projects start on a free tier to test their logic. Once they go live, they move to a “Focus” or “Stream” plan that includes gRPC. The goal is to have enough headroom so that when the market gets volatile, your app doesn’t go dark.
If you’re doing HFT or MEV, you eventually end up on an “Aperture”-style plan or a dedicated node that gives you Shredstream access. That gives you visibility into transactions while they are still propagating, which is the ultimate edge in execution.
Q: Any final advice for teams choosing their stack?
Test your provider during a period of high volatility. Anyone can look fast on a Sunday morning. Run your benchmarks when the network is screaming. If your latency spikes or your streams drop during a major market move, that provider isn’t ready for production. Reliability isn’t about uptime percentages; it’s about how the infrastructure behaves when everything else is breaking.